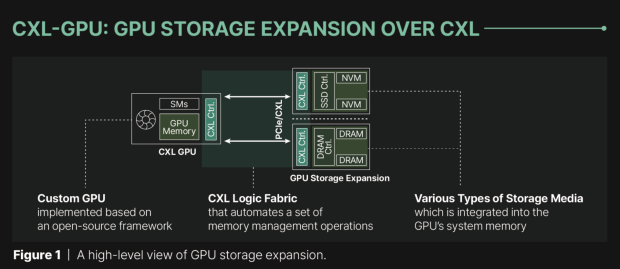
Panmnesia はおそらく今日まで聞いたことのない会社ですが、KAIST のスタートアップは、PCIe 経由の CXL プロトコルを介して AI GPU に外部メモリを追加できるようにする最先端の IP を発表しました。これにより、AI ワークロードのメモリ容量が新たなレベルに引き上げられます。
ギャラリーを見る – 画像 3 枚
Advertisement
現在の AI GPU と AI アクセラレータの群はオンボード メモリ (通常は超高速 HBM) を使用していますが、これは現在の NVIDIA Hopper H100 AI GPU の 80 GB のように少量に限られています。AMD と NVIDIA の次世代 AI チップ オファリングでは、最大 141 GB HBM3E (NVIDIA の H200 AI GPU) と最大 192 GB HBM3E (NVIDIA の B200 AI GPU、および AMD の Instinct MI300X) が導入される予定です。
しかし、現在、Panmnesia の新しい CXL IP により、GPU は DRAM や SSD のメモリにアクセスでき、内蔵 HBM メモリのメモリ容量を拡張できます。非常に便利です。韓国の研究所 (KAIST) のスタートアップは、PCIe リンクを介して CXL との接続を橋渡しするため、この新しい技術の大量導入は容易です。通常の AI アクセラレータには、メモリ拡張のために CXL に直接接続して使用するために必要なサブシステムがなく、より遅い UVM (統合仮想メモリ) などのソリューションに依存しているため、目的が完全に達成されません。ここで Panmnesia の新しい IP が役立ちます。
Panmnesia は、自社の「CXL-Opt」ソリューションを、Samsung と Meta のプロトタイプ (「CXL-Proto」と名付けた) と比較しました。CXL-Opt は、データが GPU からメモリに移動し、再びメモリに戻るまでの時間であるラウンドトリップ レイテンシがはるかに低くなっています。Panmnesia の新しい CXL-Pro は、競合他社の 250ns のレイテンシに対して、2 桁のナノ秒のレイテンシを実現しました。CXL-Opt の実行時間も UVM よりはるかに短く、IPC パフォーマンスは UVM の 3.22 倍向上しています。素晴らしいです。

Panmnesia の新しい CXL-Pro ソリューションは、HBM メモリ チップのスタックと、はるかに効率的なソリューションへの移行の間のソリューションとして機能し、AI GPU および AI アクセラレータ市場に大きな波を起こす可能性があります。Panmnesia は新しい CXL IP を最初に発表した企業の 1 つなので、ここからどのように進むのか興味深いところです。
Advertisement