
L’opinione pubblica si sta rivoltando contro l’IA su alcuni temi. Alcune persone hanno dubitato per qualche tempo dei vantaggi pratici di tutto il potere e il denaro spesi per lo sviluppo e il funzionamento dell'intelligenza artificiale, ma recentemente la leadership di diverse aziende si è completamente “mascherata” per quanto riguarda il modo in cui si sentono riguardo all'impatto dell'intelligenza artificiale. sulla società e sui suoi abitanti, e non è una bella prospettiva.
Questa citazione proviene da un'intervista di Suleyman rilasciata da Andrew Sorkin della CNBC all'Aspen Ideas Festival. Aspen Ideas Festival è una serie di seminari e panel della durata di una settimana ospitati dal think tank Aspen Institute. Nell'intervista, Sorkin pone una domanda molto ragionevole a Suleyman, che poi sbaglia completamente la risposta. Ecco la domanda e la risposta completa di Suleyman…
Sorkin: Sembra che molte delle informazioni su cui (AI) si è formata nel corso degli anni provengano dal web. Alcuni si trovano sul Web aperto, altri no. Abbiamo sentito storie su come OpenAI trasformasse i video di YouTube in trascrizioni e poi si formasse sulle trascrizioni. La domanda; chi dovrebbe possedere l'IP? Chi dovrebbe ottenere valore da quell’IP? E se, per dirla in termini molto schietti, le società di intelligenza artificiale abbiano effettivamente rubato la proprietà intellettuale mondiale?
Solimano: Penso… guarda, è un argomento molto giusto. Penso che per quanto riguarda i contenuti già presenti sul web aperto, il contratto sociale di tali contenuti, a partire dagli anni '90, è stato quello del fair use. Chiunque può copiarlo, ricrearlo, riprodurlo: che fosse freeware, se preferisci; questa è stata la comprensione. Esiste una categoria separata in cui un sito web, un editore o una testata giornalistica hanno esplicitamente detto: “non eseguire il scraping o la scansione di me per nessun altro motivo se non indicizzarmi in modo che altre persone possano trovare quel contenuto. Questa è un'area grigia e io Penso che riuscirà a farsi strada anche nei tribunali.”
Sorkin: Cosa significa quando dici che è una zona grigia?
Solimano:Beh, se, se… finora, alcune persone hanno preso queste informazioni… non so chi non l'abbia fatto… ma la questione sarà oggetto di contenzioso e penso che sia giusto che sia così.
La risposta di Suleyman ha il sapore di un tizio della tecnologia della Silicon Valley che, come gli scienziati in Jurassic Parkè così entusiasta della sua tecnologia che non ne comprende le implicazioni o le ramificazioni, tranne Suleyman che lo capisce perfettamente, o almeno dovrebbe, perché si è già trovato in una situazione simile.
Nel 2016, quando Suleyman lavorava presso Deepmind di Google, la società ha raccolto milioni di record contenenti dati di pazienti apparentemente riservati provenienti da ospedali gestiti dal Servizio sanitario nazionale del Regno Unito. L’accordo di condivisione dei dati è andato ben oltre quanto annunciato pubblicamente ed è stato stipulato in gran parte senza il consenso dei pazienti in questione, nonostante i registri includessero dati quotidiani sulle operazioni ospedaliere e sui movimenti dei pazienti. Di fronte alle critiche sulle azioni di Deepmind, il cofondatore dell'azienda Suleyman si è mostrato sprezzante, affermando che le persone che si sono opposte all'accordo di condivisione dei dati erano “guidate da un gruppo con un vista particolare da spacciare.”
Advertisement
Allora, come adesso, il suo atteggiamento era quello di avere il diritto di utilizzare i dati di altre persone per i propri scopi, e chiunque si opponga è solo un odiatore. Parla da un luogo di immenso privilegio, arroganza e ignoranza, o entrambi, della realtà dell'essere un lavoratore creativo nel 2024 e della legge sul copyright, perché non esiste un “contratto sociale di libero utilizzo” in vigore sui contenuti web. Per esempio, HotHardware stesso vieta l'uso dei suoi contenuti con avvisi di copyright saldamente in vigore.
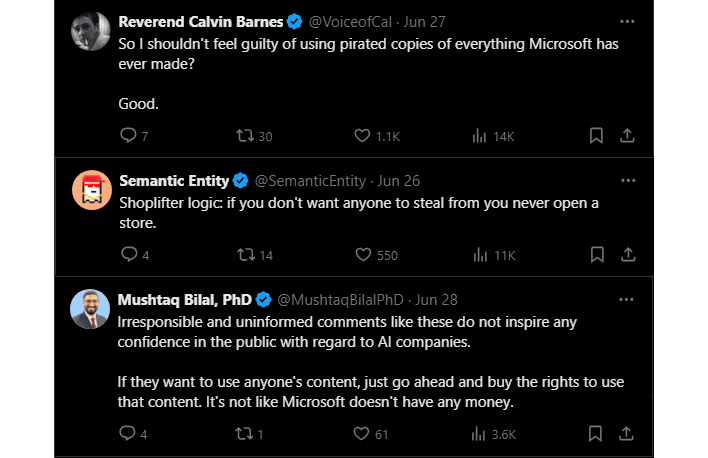
Gli utenti sui social media hanno criticato duramente i commenti di Suleyman, compresi i post sopra. Ci piace particolarmente il post che definisce la sua mentalità “logica da taccheggiatore”, poiché incapsula completamente la sua linea di pensiero, specialmente la parte in cui prosegue affermando che le aziende di intelligenza artificiale continueranno a rubare il duro lavoro dei creativi come noi qui a HotHardware finché non li denunceremo per questo. È un atteggiamento molto distopico.
Advertisement
Siamo principalmente una pubblicazione di notizie e recensioni tecnologiche, quindi ovviamente siamo ben consapevoli del potenziale dell'IA per accelerare i flussi di lavoro e semplificare la vita degli esseri umani. Siamo anche fin troppo consapevoli del potenziale dell'IA di fare del male. Per Suleyman, descrivere la maggior parte dei contenuti sul web aperto come “freeware”, aperti alla presa, è un sentimento orribile per il quale speriamo che Suleyman venga duramente castigato.