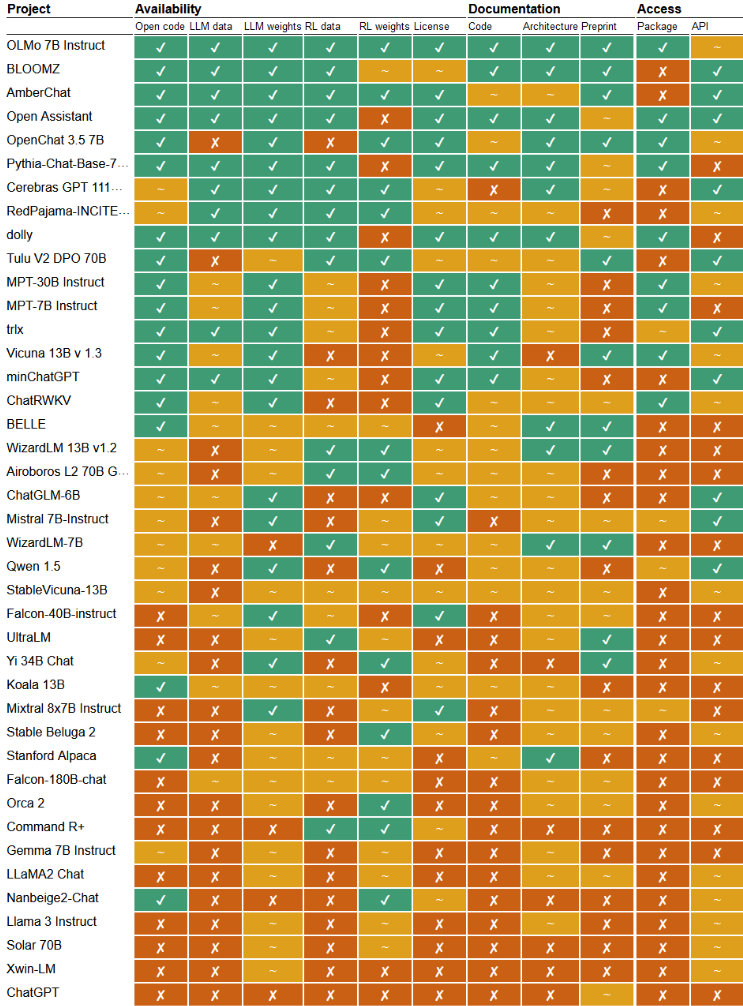
Researchers from the University of Nijmegen (Netherlands) prepared openness rating of 40 large language models and 7 models for generating images from text descriptions, which are declared by manufacturers as open. Due to the fact that the criteria for the openness of machine learning models are still are being formed, a situation has now arisen where models are distributed under the guise of open source models that have a license that limits their scope of use (for example, many models prohibit use in commercial projects). Also, often manufacturers do not provide access to the data used in training, do not disclose implementation details, or do not fully open the accompanying code.
Most models marketed as “open” should in fact be thought of as “open weights” or more accurately “accessible weights” because they are distributed under restrictive licenses that prohibit use in commercial products. Outside researchers can experiment with similar models, but are not able to tailor the model to their needs or inspect the implementation. More than half of the models do not provide detailed information about the data used for training, nor do they publish information about the internal design and architecture.
Advertisement
Models recognized as the most open BloomZ, AmberChat, OLMo, Open Assistant And Stable Diffusion, which are published under open licenses along with source data, code, and API implementations. Models from Google (Gemma 7B), Microsoft (Orca 2) and Meta (Llama 3), positioned by manufacturers as open, were closer to the bottom of the ranking, since they do not provide access to source data, do not disclose technical details of implementation, and model weights are distributed under licenses that limit the scope of use. The popular Mistral 7B model was approximately in the middle of the rating, as it is supplied under an open license, but is only partially documented, does not disclose the data used in training, and does not have fully open accompanying code.
The researchers proposed 14 criteria for the openness of AI models, covering the distribution of code, training data, weights, data variants and coefficients optimized using reinforcement learning (RL), as well as the availability of ready-to-use packages, APIs, documentation and detailed descriptions implementation.

Thanks for reading:
Advertisement